Validate lint docs separately.
This addresses some concerns raised in https://github.com/rust-lang/rust/pull/76549#issuecomment-727638552 about errors with the lint docs being confusing and cumbersome. Errors from validating the lint documentation were being generated during `x.py doc` (and `x.py dist`), since extraction and validation are being done in a single step. This changes it so that extraction and validation are separated, so that `x.py doc` will not error if there is a validation problem, and tests are moved to `x.py test src/tools/lint-docs`.
This includes the following changes:
* Separate validation to `x.py test`.
* Added some more documentation on how to more easily modify and test the docs.
* Added more help to the error messages to hopefully provide more information on how to fix things.
The first commit just moves the code around, so you may consider looking at the other commits for a smaller diff.
Stop adding '*' at the end of slice and str typenames for MSVC case
When computing debug info for MSVC debuggers, Rust compiler emits C++ style type names for compatibility with .natvis visualizers. All Ref types are treated as equivalences of C++ pointers in this process, and, as a result, their type names end with a '\*'. Since Slice and Str are treated as Ref by the compiler, their type names also end with a '\*'. This causes the .natvis engine for WinDbg fails to display data of Slice and Str objects. We addressed this problem simply by removing the '*' at the end of type names for Slice and Str types.
Debug info in WinDbg before the fix:

Debug info in WinDbg after the fix:
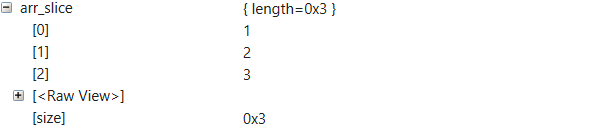
This change has also been tested with debuggers for Visual Studio, VS Code C++ and VS Code LLDB to make sure that it does not affect the behavior of other kinds of debugger.
This checks the error code returned by `dsymutil` and warns if it failed. It
also provides the stdout and stderr logs from `dsymutil`, similar to the native
linker step.
Fixes https://github.com/rust-lang/rust/issues/78770
Update error to reflect that integer literals can have float suffixes
For example, `1` is parsed as an integer literal, but it can be turned
into a float with the suffix `f32`. Now the error calls them "numeric
literals" and notes that you can add a float suffix since they can be
either integers or floats.
Fix overlap detection of `usize`/`isize` range patterns
`usize` and `isize` are a bit of a special case in the match usefulness algorithm, because the range of values they contain depends on the platform. Specifically, we don't want `0..usize::MAX` to count as an exhaustive match (see also [`precise_pointer_size_matching`](https://github.com/rust-lang/rust/issues/56354)). The way this was initially implemented is by treating those ranges like float ranges, i.e. with limited cleverness. This means we didn't catch the following as unreachable:
```rust
match 0usize {
0..10 => {},
10..20 => {},
5..15 => {}, // oops, should be detected as unreachable
_ => {},
}
```
This PRs fixes this oversight. Now the only difference between `usize` and `u64` range patterns is in what ranges count as exhaustive.
r? `@varkor`
`@rustbot` label +A-exhaustiveness-checking
This commit modifies the `check_attr` pass so that attribute placement
on generic parameters is checked for validity.
Signed-off-by: David Wood <david@davidtw.co>
Don't run `resolve_vars_if_possible` in `normalize_erasing_regions`
Neither `@eddyb` nor I could figure out what this was for. I changed it to `assert_eq!(normalized_value, infcx.resolve_vars_if_possible(&normalized_value));` and it passed the UI test suite.
<details><summary>
Outdated, I figured out the issue - `needs_infer()` needs to come _after_ erasing the lifetimes
</summary>
Strangely, if I change it to `assert!(!normalized_value.needs_infer())` it panics almost immediately:
```
query stack during panic:
#0 [normalize_generic_arg_after_erasing_regions] normalizing `<str::IsWhitespace as str::pattern::Pattern>::Searcher`
#1 [needs_drop_raw] computing whether `str::iter::Split<str::IsWhitespace>` needs drop
#2 [mir_built] building MIR for `str::<impl str>::split_whitespace`
#3 [unsafety_check_result] unsafety-checking `str::<impl str>::split_whitespace`
#4 [mir_const] processing MIR for `str::<impl str>::split_whitespace`
#5 [mir_promoted] processing `str::<impl str>::split_whitespace`
#6 [mir_borrowck] borrow-checking `str::<impl str>::split_whitespace`
#7 [analysis] running analysis passes on this crate
end of query stack
```
I'm not entirely sure what's going on - maybe the two disagree?
</details>
For context, this came up while reviewing https://github.com/rust-lang/rust/pull/77467/ (cc `@lcnr).`
Possibly this needs a crater run?
r? `@nikomatsakis`
cc `@matthewjasper`
Support repr(simd) on ADTs containing a single array field
This is a squash and rebase of `@gnzlbg's` #63531
I've never actually written code in the compiler before so just fumbled my way around until it would build 😅
I imagine there'll be some work we need to do in `rustc_codegen_cranelift` too for this now, but might need some input from `@bjorn3` to know what that is.
cc `@rust-lang/project-portable-simd`
-----
This PR allows using `#[repr(simd)]` on ADTs containing a single array field:
```rust
#[repr(simd)] struct S0([f32; 4]);
#[repr(simd)] struct S1<const N: usize>([f32; N]);
#[repr(simd)] struct S2<T, const N: usize>([T; N]);
```
This should allow experimenting with portable packed SIMD abstractions on nightly that make use of const generics.
Extend doc keyword feature by allowing any ident
Part of #51315.
As suggested by ``@danielhenrymantilla`` in [this comment](https://github.com/rust-lang/rust/issues/51315#issuecomment-733879934), this PR extends `#[doc(keyword = "...")]` to allow any ident to be used as keyword. The final goal is to allow (proc-)macro crates' owners to write documentation of the keywords they might introduce.
r? ``@jyn514``
Sync rustc_codegen_cranelift
This implements a few extra simd intrinsics, fixes yet another 128bit bug and updates a few dependencies. It also fixes an cg_clif subtree update that did compile, but that caused a panic when compiling libcore. Other than that this is mostly cleanups.
`@rustbot` modify labels: +A-codegen +A-cranelift +T-compiler
rustc_parse: fix ConstBlock expr span
The span for a ConstBlock expression should presumably run through the end of the block it contains and not stop at the keyword, just like is done with similar block-containing expression kinds, such as a TryBlock
Properly handle attributes on statements
We now collect tokens for the underlying node wrapped by `StmtKind`
nstead of storing tokens directly in `Stmt`.
`LazyTokenStream` now supports capturing a trailing semicolon after it
is initially constructed. This allows us to avoid refactoring statement
parsing to wrap the parsing of the semicolon in `parse_tokens`.
Attributes on item statements
(e.g. `fn foo() { #[bar] struct MyStruct; }`) are now treated as
item attributes, not statement attributes, which is consistent with how
we handle attributes on other kinds of statements. The feature-gating
code is adjusted so that proc-macro attributes are still allowed on item
statements on stable.
Two built-in macros (`#[global_allocator]` and `#[test]`) needed to be
adjusted to support being passed `Annotatable::Stmt`.
For example, `1` is parsed as an integer literal, but it can be turned
into a float with the suffix `f32`. Now the error calls them "numeric
literals" and notes that you can add a float suffix since they can be
either integers or floats.
Split match exhaustiveness into two files
I feel the constructor-related things in the `_match` module make enough sense on their own so I split them off. It makes `_match` feel less like a complicated mess. I'm not aware of PRs in progress against this module apart from my own so hopefully I'm not annoying too many people.
I have a lot of questions about the conventions in naming and modules around the compiler. Like, why is the module named `_match`? Could I rename it to `usefulness` maybe? Should `deconstruct_pat` be a submodule of `_match` since only `_match` uses it? Is it ok to move big piles of code around even if it makes git blame more difficult?
r? `@varkor`
`@rustbot` modify labels: +A-exhaustiveness-checking
{kind=link}
{kind=link}