Stabilize some `ascii_ctype` methods
As discussed in #39658, this PR stabilizes those methods for `u8` and `char`. All inherent `ascii_ctype` for `[u8]` and `str` are removed as we prefer the more explicit version `s.chars().all(|c| c.is_ascii_())`.
This PR doesn't modify the `AsciiExt` trait. There, the `ascii_ctype` methods are still unstable. It is planned to remove those in the future (I think). I had to modify some code in `ascii.rs` to properly implement `AsciiExt` for all types.
Fixes#39658.
Add std::sync::mpsc::Receiver::recv_deadline()
Essentially renames recv_max_until to recv_deadline (mostly copying recv_timeout
documentation). This function is useful to avoid the often unnecessary call to
Instant::now in recv_timeout (e.g. when the user already has a deadline). A
concrete example would be something along those lines:
```rust
use std::sync::mpsc::Receiver;
use std::time::{Duration, Instant};
/// Reads a batch of elements
///
/// Returns as soon as `max_size` elements have been received or `timeout` expires.
fn recv_batch_timeout<T>(receiver: &Receiver<T>, timeout: Duration, max_size: usize) -> Vec<T> {
recv_batch_deadline(receiver, Instant::now() + timeout, max_size)
}
/// Reads a batch of elements
///
/// Returns as soon as `max_size` elements have been received or `deadline` is reached.
fn recv_batch_deadline<T>(receiver: &Receiver<T>, deadline: Instant, max_size: usize) -> Vec<T> {
let mut result = Vec::new();
while let Ok(x) = receiver.recv_deadline(deadline) {
result.push(x);
if result.len() == max_size {
break;
}
}
result
}
```
Implement From<RecvError> for TryRecvError and RecvTimeoutError
According to the documentation, it looks to me that `TryRecvError` and `RecvTimeoutError` are strict extensions of `RecvError`. As such, it makes sense to allow conversion from the latter type to the two former types without constraining future developments.
This permits to write `input.recv()?` and `input.recv_timeout(timeout)?` in the same function for example.
Provides the following conversion implementations:
* `From<`{`CString`,`&CStr`}`>` for {`Arc`,`Rc`}`<CStr>`
* `From<`{`OsString`,`&OsStr`}`>` for {`Arc`,`Rc`}`<OsStr>`
* `From<`{`PathBuf`,`&Path`}`>` for {`Arc`,`Rc`}`<Path>`
This commit alters how we compile LLVM by default enabling the WebAssembly
backend. This then also adds the wasm32-unknown-unknown target to get compiled
on the `cross` builder and distributed through rustup. Tests are not yet enabled
for this target but that should hopefully be coming soon!
Turns out ThinLTO was internalizing this symbol and eliminating it. Worse yet if
you compiled with LTO turns out no TLS destructors would run on Windows! The
`#[used]` annotation should be a more bulletproof implementation (in the face of
LTO) of preserving this symbol all the way through in LLVM and ensuring it makes
it all the way to the linker which will take care of it.
The current implementation/documentation was made to avoid sNaN because of
potential safety issues implied by old/bad LLVM documentation. These issues
aren't real, so we can just make the implementation transmute (as permitted
by the existing documentation of this method).
Also the documentation didn't actually match the behaviour: it said we may
change sNaNs, but in fact we canonicalized *all* NaNs.
Also an example in the documentation was wrong: it said we *always* change
sNaNs, when the documentation was explicitly written to indicate it was
implementation-defined.
This makes to_bits and from_bits perfectly roundtrip cross-platform, except
for one caveat: although the 2008 edition of IEEE-754 specifies how to
interpet the signaling bit, earlier editions didn't. This lead to some platforms
picking the opposite interpretation, so all signaling NaNs on x86/ARM are quiet
on MIPS, and vice-versa.
NaN-boxing is a fairly important optimization, while we don't even guarantee
that float operations properly preserve signalingness. As such, this seems like
the more natural strategy to take (as opposed to trying to mangle the signaling
bit on a per-platform basis).
This implementation is also, of course, faster.
Optimize `read_to_end`.
This patch makes `read_to_end` use Vec's memory-growth pattern rather
than using a custom pattern.
This has some interesting effects:
- If memory is reserved up front, `read_to_end` can be faster, as it
starts reading at the buffer size, rather than always starting at 32
bytes. This speeds up file reading by 2x in one of my use cases.
- It can reduce the number of syscalls when reading large files.
Previously, `read_to_end` would settle into a sequence of 8192-byte
reads. With this patch, the read size follows Vec's allocation
pattern. For example, on a 16MiB file, it can do 21 read syscalls
instead of 2057. In simple benchmarks of large files though, overall
speed is still dominated by the actual I/O.
- A downside is that Read implementations that don't implement
`initializer()` may see increased memory zeroing overhead.
I benchmarked this on a variety of data sizes, with and without
preallocated buffers. Most benchmarks see no difference, but reading
a small/medium file with a pre-allocated buffer is faster.
show in docs whether the return type of a function impls Iterator/Read/Write
Closes#25928
This PR makes it so that when rustdoc documents a function, it checks the return type to see whether it implements a handful of specific traits. If so, it will print the impl and any associated types. Rather than doing this via a whitelist within rustdoc, i chose to do this by a new `#[doc]` attribute parameter, so things like `Future` could tap into this if desired.
### Known shortcomings
~~The printing of impls currently uses the `where` class over the whole thing to shrink the font size relative to the function definition itself. Naturally, when the impl has a where clause of its own, it gets shrunken even further:~~ (This is no longer a problem because the design changed and rendered this concern moot.)
The lookup currently just looks at the top-level type, not looking inside things like Result or Option, which renders the spotlights on Read/Write a little less useful:
<details><summary>`File::{open, create}` don't have spotlight info (pic of old design)</summary>
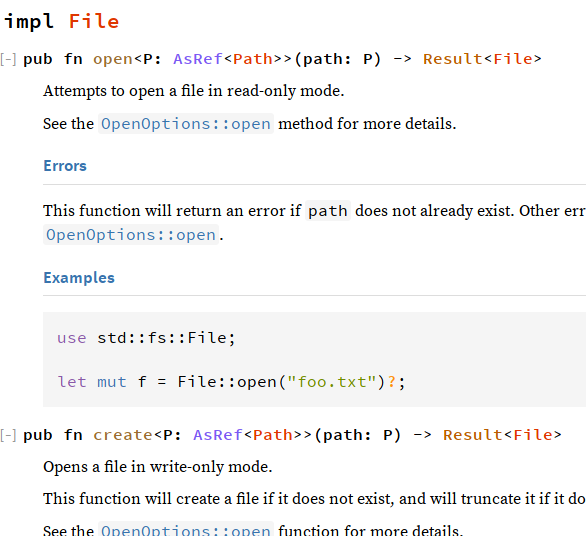
</details>
All three of the initially spotlighted traits are generically implemented on `&mut` references. Rustdoc currently treats a `&mut T` reference-to-a-generic as an impl on the reference primitive itself. `&mut Self` counts as a generic in the eyes of rustdoc. All this combines to create this lovely scene on `Iterator::by_ref`:
<details><summary>`Iterator::by_ref` spotlights Iterator, Read, and Write (pic of old design)</summary>
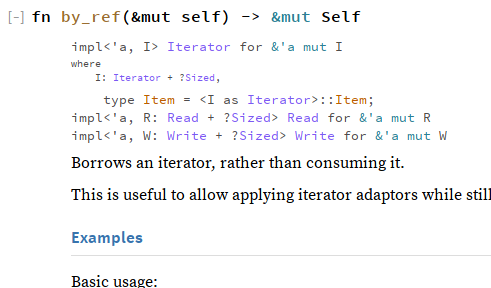
</details>
add doc for doing `Read` from `&str`
This information can be found on [stackoverflow](https://stackoverflow.com/questions/32674905/pass-string-to-function-taking-read-trait) but I think it would be beneficial if it was documented in the `Read` trait itself.
I had an *extremely* hard time finding this information, and "mocking" a reader with a string is an EXTREMELY common thing (I believe).
impl From for Mutex and RwLock
I felt that these implementations were missing, because doing `x.into()` works for other smart containers (such as `RefCell`), and in general I would say that the conversion makes sense.
This commit adds a new target to the compiler: wasm32-unknown-unknown. This
target is a reimagining of what it looks like to generate WebAssembly code from
Rust. Instead of using Emscripten which can bring with it a weighty runtime this
instead is a target which uses only the LLVM backend for WebAssembly and a
"custom linker" for now which will hopefully one day be direct calls to lld.
Notable features of this target include:
* There is zero runtime footprint. The target assumes nothing exists other than
the wasm32 instruction set.
* There is zero toolchain footprint beyond adding the target. No custom linker
is needed, rustc contains everything.
* Very small wasm modules can be generated directly from Rust code using this
target.
* Most of the standard library is stubbed out to return an error, but anything
related to allocation works (aka `HashMap`, `Vec`, etc).
* Naturally, any `#[no_std]` crate should be 100% compatible with this new
target.
This target is currently somewhat janky due to how linking works. The "linking"
is currently unconditional whole program LTO (aka LLVM is being used as a
linker). Naturally that means compiling programs is pretty slow! Eventually
though this target should have a linker.
This target is also intended to be quite experimental. I'm hoping that this can
act as a catalyst for further experimentation in Rust with WebAssembly. Breaking
changes are very likely to land to this target, so it's not recommended to rely
on it in any critical capacity yet. We'll let you know when it's "production
ready".
---
Currently testing-wise this target is looking pretty good but isn't complete.
I've got almost the entire `run-pass` test suite working with this target (lots
of tests ignored, but many passing as well). The `core` test suite is still
getting LLVM bugs fixed to get that working and will take some time. Relatively
simple programs all seem to work though!
---
It's worth nothing that you may not immediately see the "smallest possible wasm
module" for the input you feed to rustc. For various reasons it's very difficult
to get rid of the final "bloat" in vanilla rustc (again, a real linker should
fix all this). For now what you'll have to do is:
cargo install --git https://github.com/alexcrichton/wasm-gc
wasm-gc foo.wasm bar.wasm
And then `bar.wasm` should be the smallest we can get it!
---
In any case for now I'd love feedback on this, particularly on the various
integration points if you've got better ideas of how to approach them!
This has been discussed in #39658. It's a bit ambiguous how those
methods work for a sequence of ascii values. We prefer users writing
`s.iter().all(|b| b.is_ascii_...())` explicitly.
The AsciiExt methods still exist and are implemented for `str`
and `[u8]`. We will deprecated or remove those later.
This patch makes `read_to_end` use Vec's memory-growth pattern rather
than using a custom pattern.
This has some interesting effects:
- If memory is reserved up front, `read_to_end` can be faster, as it
starts reading at the buffer size, rather than always starting at 32
bytes. This speeds up file reading by 2x in one of my use cases.
- It can reduce the number of syscalls when reading large files.
Previously, `read_to_end` would settle into a sequence of 8192-byte
reads. With this patch, the read size follows Vec's allocation
pattern. For example, on a 16MiB file, it can do 21 read syscalls
instead of 2057. In simple benchmarks of large files though, overall
speed is still dominated by the actual I/O.
- A downside is that Read implementations that don't implement
`initializer()` may see increased memory zeroing overhead.
I benchmarked this on a variety of data sizes, with and without
preallocated buffers. Most benchmarks see no difference, but reading
a small/medium file with a pre-allocated buffer is faster.
Use getrandom syscall for all Linux and Android targets.
I suppose we can use it in all Linux and Android targets. In function `is_getrandom_available` is checked if the syscall is available (getrandom syscall was add in version 3.17 of Linux kernel), if the syscall is not available `fill_bytes` fallback to reading from `/dev/urandom`.
Update libc to include getrandom related constants.
Essentially renames recv_max_until to recv_deadline (mostly copying recv_timeout
documentation). This function is useful to avoid the often unnecessary call to
Instant::now in recv_timeout (e.g. when the user already has a deadline). A
concrete example would be something along those lines:
```rust
use std::sync::mpsc::Receiver;
use std::time::{Duration, Instant};
/// Reads a batch of elements
///
/// Returns as soon as `max_size` elements have been received or `timeout` expires.
fn recv_batch_timeout<T>(receiver: &Receiver<T>, timeout: Duration, max_size: usize) -> Vec<T> {
recv_batch_deadline(receiver, Instant::now() + timeout, max_size)
}
/// Reads a batch of elements
///
/// Returns as soon as `max_size` elements have been received or `deadline` is reached.
fn recv_batch_deadline<T>(receiver: &Receiver<T>, deadline: Instant, max_size: usize) -> Vec<T> {
let mut result = Vec::new();
while let Ok(x) = receiver.recv_deadline(deadline) {
result.push(x);
if result.len() == max_size {
break;
}
}
result
}
```
Redox: Use futex timeout to implement CondVar::wait_timeout
`CondVar::wait_timeout` is implemented by supplying a `TimeSpec` pointer to `futex`. In addition, all calls to `unimplemented!()` have been removed from the Redox `sys` module.
Related to https://github.com/rust-lang/rust/pull/45892
Redox: Return true from Path::is_absolute if a Path contains root or a scheme
In Redox, different subsystems have different filesystem paths. However, the majority of applications using the `Path::is_absolute` function really only want to know if a path is absolute from the perspective of the scheme it is currently running in, usually `file:`. This makes both `file:/` and `/` return `true` from `Path::is_absolute`, meaning that most code does not have to check if it is running on Redox.
Code that wants to know if a path contains a scheme can implement such a check on its own.
Related to https://github.com/rust-lang/rust/pull/45893
Addressed issues raised in #44286. (`OccupiedEntry::replace_entry`)
This commit renames the `replace` function to `replace_entry`, and
creates a seperate `replace_key` function for `OccupiedEntry`. The
original `replace` function did not solve the use-case where the
key needed to be replaced, but not the value. Documentation and
naming has also been updated to better reflect what the original
replace function does.
{kind=link}
{kind=link}