interpret: get rid of MemPlaceMeta::Poison
This is achieved by refactoring the projection code (`{mplace,place,operand}_{downcast,field,index,...}`) so that we no longer need to call `assert_mem_place` in the operand handling.
Pull Derefer before ElaborateDrops
_Follow up work to #97025#96549#96116#95887 #95649_
This moves `Derefer` before `ElaborateDrops` and creates a new `Rvalue` called `VirtualRef` that allows us to bypass many constraints for `DerefTemp`.
r? `@oli-obk`
don't allow ZST in ScalarInt
There are several indications that we should not ZST as a ScalarInt:
- We had two ways to have ZST valtrees, either an empty `Branch` or a `Leaf` with a ZST in it.
`ValTree::zst()` used the former, but the latter could possibly arise as well.
- Likewise, the interpreter had `Immediate::Uninit` and `Immediate::Scalar(Scalar::ZST)`.
- LLVM codegen already had to special-case ZST ScalarInt.
So I propose we stop using ScalarInt to represent ZST (which are clearly not integers). Instead, we can add new ZST variants to those types that did not have other variants which could be used for this purpose.
Based on https://github.com/rust-lang/rust/pull/98831. Only the commits starting from "don't allow ZST in ScalarInt" are new.
r? `@oli-obk`
There are several indications that we should not ZST as a ScalarInt:
- We had two ways to have ZST valtrees, either an empty `Branch` or a `Leaf` with a ZST in it.
`ValTree::zst()` used the former, but the latter could possibly arise as well.
- Likewise, the interpreter had `Immediate::Uninit` and `Immediate::Scalar(Scalar::ZST)`.
- LLVM codegen already had to special-case ZST ScalarInt.
So instead add new ZST variants to those types that did not have other variants
which could be used for this purpose.
Clarify MIR semantics of storage statements
Seems worthwhile to start closing out some of the less controversial open questions about MIR semantics. Hopefully this is fairly non-controversial - it's what we implement already, and I see no reason to do anything more restrictive. cc ``@tmiasko`` who commented on this when it was discussed in the original PR that added these docs.
interpret: use AllocRange in UninitByteAccess
also use nice new format string syntax in `interpret/error.rs`, and use the `#` flag to add `0x` prefixes where applicable.
r? ``@oli-obk``
This makes it possible to mutably borrow different fields of the MIR
body without resorting to methods like `basic_blocks_local_decls_mut_and_var_debug_info`.
To preserve validity of control flow graph caches in the presence of
modifications, a new struct `BasicBlocks` wraps together basic blocks
and control flow graph caches.
The `BasicBlocks` dereferences to `IndexVec<BasicBlock, BasicBlockData>`.
On the other hand a mutable access requires explicit `as_mut()` call.
Interpret: AllocRange Debug impl, and use it more consistently
The two commits are pretty independent but it did not seem worth having two PRs for them.
r? ``@oli-obk``
Add method to mutate MIR body without invalidating CFG caches.
In addition to adding this method, a handful of passes are updated to use it. There's still quite a few passes that could in principle make use of this as well, but do not at the moment because they use `VisitorMut` or `MirPatch`, which needs additional support for this.
The method name is slightly unwieldy, but I don't expect anyone to be writing it a lot, and at least it says what it does. If anyone has a suggestion for a better name though, would be happy to rename.
r? rust-lang/mir-opt
CTFE interning: don't walk allocations that don't need it
The interning of const allocations visits the mplace looking for references to intern. Walking big aggregates like big static arrays can be costly, so we only do it if the allocation we're interning contains references or interior mutability.
Walking ZSTs was avoided before, and this optimization is now applied to cases where there are no references/relocations either.
---
While initially looking at this in the context of #93215, I've been testing with smaller allocations than the 16GB one in that issue, and with different init/uninit patterns (esp. via padding).
In that example, by default, `eval_to_allocation_raw` is the heaviest query followed by `incr_comp_serialize_result_cache`. So I'll show numbers when incremental compilation is disabled, to focus on the const allocations themselves at 95% of the compilation time, at bigger array sizes on these minimal examples like `static ARRAY: [u64; LEN] = [0; LEN];`.
That is a close construction to parts of the `ctfe-stress-test-5` benchmark, which has const allocations in the megabytes, while most crates usually have way smaller ones. This PR will have the most impact in these situations, as the walk during the interning starts to dominate the runtime.
Unicode crates (some of which are present in our benchmarks) like `ucd`, `encoding_rs`, etc come to mind as having bigger than usual allocations as well, because of big tables of code points (in the hundreds of KB, so still an order of magnitude or 2 less than the stress test).
In a check build, for a single static array shown above, from 100 to 10^9 u64s (for lengths in powers of ten), the constant factors are lowered:
(log scales for easier comparisons)
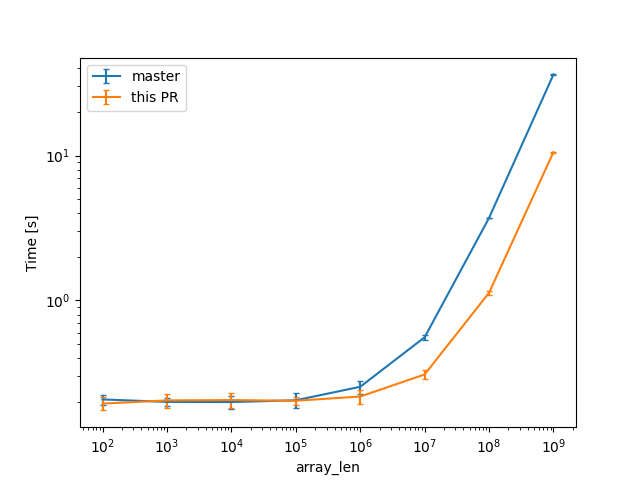
(linear scale for absolute diff at higher Ns)
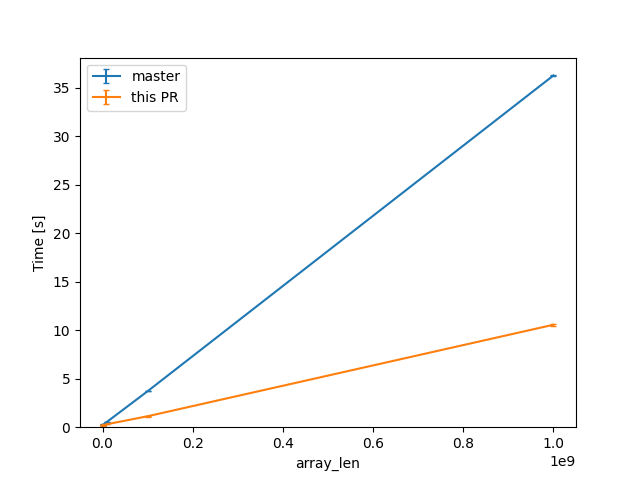
For one of the alternatives of that issue
```rust
const ROWS: usize = 100_000;
const COLS: usize = 10_000;
static TWODARRAY: [[u128; COLS]; ROWS] = [[0; COLS]; ROWS];
```
we can see a similar reduction of around 3x (from 38s to 12s or so).
For the same size, the slowest case IIRC is when there are uninitialized bytes e.g. via padding
```rust
const ROWS: usize = 100_000;
const COLS: usize = 10_000;
static TWODARRAY: [[(u64, u8); COLS]; ROWS] = [[(0, 0); COLS]; ROWS];
```
then interning/walking does not dominate anymore (but means there is likely still some interesting work left to do here).
Compile times in this case rise up quite a bit, and avoiding interning walks has less impact: around 23%, from 730s on master to 568s with this PR.
move MIR syntax into a dedicated file and ping some people whenever it changes
Adding or changing MIR operations/statements/whatever should be under significant scrutiny wrt their wider impact, specified semantics, and so on. So let's start by putting all that into a dedicated file and pinging some people whenever that file changes.
This PR only moves definitions around, and then fiddles with imports until it all works again.
{kind=link}
{kind=link}
{kind=link}