[perf] Delay the construction of early lint diag structs
Attacks some of the perf regressions from https://github.com/rust-lang/rust/pull/124417#issuecomment-2123700666.
See individual commits for details. The first three commits are not strictly necessary.
However, the 2nd one (06bc4fc671, *Remove `LintDiagnostic::msg`*) makes the main change way nicer to implement.
It's also pretty sweet on its own if I may say so myself.
* instead simply set the primary message inside the lint decorator functions
* it used to be this way before [#]101986 which introduced `msg` to prevent
good path delayed bugs (which no longer exist) from firing under certain
circumstances when lints were suppressed / silenced
* this is no longer necessary for various reasons I presume
* it shaves off complexity and makes further changes easier to implement
Existing names for values of this type are `sess`, `parse_sess`,
`parse_session`, and `ps`. `sess` is particularly annoying because
that's also used for `Session` values, which are often co-located, and
it can be difficult to know which type a value named `sess` refers to.
(That annoyance is the main motivation for this change.) `psess` is nice
and short, which is good for a name used this much.
The commit also renames some `parse_sess_created` values as
`psess_created`.
It currently is infallible and uses `abort_if_errors` and
`FatalError.raise()` to signal errors. It's easy to instead return a
`Result<_, ErrorGuaranteed>`, which is the more usual way of doing
things.
Currently `has_errors` excludes lint errors. This commit changes it to
include lint errors.
The motivation for this is that for most places it doesn't matter
whether lint errors are included or not. But there are multiple places
where they must be includes, and only one place where they must not be
included. So it makes sense for `has_errors` to do the thing that fits
the most situations, and the new `has_errors_excluding_lint_errors`
method in the one exceptional place.
The same change is made for `err_count`. Annoyingly, this requires the
introduction of `err_count_excluding_lint_errs` for one place, to
preserve existing error printing behaviour. But I still think the change
is worthwhile overall.
Error codes are integers, but `String` is used everywhere to represent
them. Gross!
This commit introduces `ErrCode`, an integral newtype for error codes,
replacing `String`. It also introduces a constant for every error code,
e.g. `E0123`, and removes the `error_code!` macro. The constants are
imported wherever used with `use rustc_errors::codes::*`.
With the old code, we have three different ways to specify an error code
at a use point:
```
error_code!(E0123) // macro call
struct_span_code_err!(dcx, span, E0123, "msg"); // bare ident arg to macro call
\#[diag(name, code = "E0123")] // string
struct Diag;
```
With the new code, they all use the `E0123` constant.
```
E0123 // constant
struct_span_code_err!(dcx, span, E0123, "msg"); // constant
\#[diag(name, code = E0123)] // constant
struct Diag;
```
The commit also changes the structure of the error code definitions:
- `rustc_error_codes` now just defines a higher-order macro listing the
used error codes and nothing else.
- Because that's now the only thing in the `rustc_error_codes` crate, I
moved it into the `lib.rs` file and removed the `error_codes.rs` file.
- `rustc_errors` uses that macro to define everything, e.g. the error
code constants and the `DIAGNOSTIC_TABLES`. This is in its new
`codes.rs` file.
We have several methods indicating the presence of errors, lint errors,
and delayed bugs. I find it frustrating that it's very unclear which one
you should use in any particular spot. This commit attempts to instill a
basic principle of "use the least general one possible", because that
reflects reality in practice -- `has_errors` is the least general one
and has by far the most uses (esp. via `abort_if_errors`).
Specifics:
- Add some comments giving some usage guidelines.
- Prefer `has_errors` to comparing `err_count` to zero.
- Remove `has_errors_or_span_delayed_bugs` because it's a weird one: in
the cases where we need to count delayed bugs, we should really be
counting lint errors as well.
- Rename `is_compilation_going_to_fail` as
`has_errors_or_lint_errors_or_span_delayed_bugs`, for consistency with
`has_errors` and `has_errors_or_lint_errors`.
- Change a few other `has_errors_or_lint_errors` calls to `has_errors`,
as per the "least general" principle.
This didn't turn out to be as neat as I hoped when I started, but I
think it's still an improvement.
In #119606 I added them and used a `_mv` suffix, but that wasn't great.
A `with_` prefix has three different existing uses.
- Constructors, e.g. `Vec::with_capacity`.
- Wrappers that provide an environment to execute some code, e.g.
`with_session_globals`.
- Consuming chaining methods, e.g. `Span::with_{lo,hi,ctxt}`.
The third case is exactly what we want, so this commit changes
`DiagnosticBuilder::foo_mv` to `DiagnosticBuilder::with_foo`.
Thanks to @compiler-errors for the suggestion.
Because it takes an error code after the span. This avoids the confusing
overlap with the `DiagCtxt::struct_span_err` method, which doesn't take
an error code.
By storing the unparsed values in `Config` and then parsing them within
`run_compiler`, the parsing functions can use the main symbol interner,
and not create their own short-lived interners.
This change also eliminates the need for one `EarlyErrorHandler` in
rustdoc, because parsing errors can be reported by another, slightly
later `EarlyErrorHandler`.
`parse_cfgspecs` and `parse_check_cfg` run very early, before the main
interner is running. They each use a short-lived interner and convert
all interned symbols to strings in their output data structures. Once
the main interner starts up, these data structures get converted into
new data structures that are identical except with the strings converted
to symbols.
All is not obvious from the current code, which is a mess, particularly
with inconsistent naming that obscures the parallel string/symbol data
structures. This commit clean things up a lot.
- The existing `CheckCfg` type is generic, allowing both
`CheckCfg<String>` and `CheckCfg<Symbol>` forms. This is really
useful, but it defaults to `String`. The commit removes the default so
we have to use `CheckCfg<String>` and `CheckCfg<Symbol>` explicitly,
which makes things clearer.
- Introduces `Cfg`, which is generic over `String` and `Symbol`, similar
to `CheckCfg`.
- Renames some things.
- `parse_cfgspecs` -> `parse_cfg`
- `CfgSpecs` -> `Cfg<String>`, plus it's used in more places, rather
than the underlying `FxHashSet` type.
- `CrateConfig` -> `Cfg<Symbol>`.
- `CrateCheckConfig` -> `CheckCfg<Symbol>`
- Adds some comments explaining the string-to-symbol conversions.
- `to_crate_check_config`, which converts `CheckCfg<String>` to
`CheckCfg<Symbol>`, is inlined and removed and combined with the
overly-general `CheckCfg::map_data` to produce
`CheckCfg::<String>::intern`.
- `build_configuration` now does the `Cfg<String>`-to-`Cfg<Symbol>`
conversion, so callers don't need to, which removes the need for
`to_crate_config`.
The diff for two of the fields in `Config` is a good example of the
improved clarity:
```
- pub crate_cfg: FxHashSet<(String, Option<String>)>,
- pub crate_check_cfg: CheckCfg,
+ pub crate_cfg: Cfg<String>,
+ pub crate_check_cfg: CheckCfg<String>,
```
Compare that with the diff for the corresponding fields in `ParseSess`,
and the relationship to `Config` is much clearer than before:
```
- pub config: CrateConfig,
- pub check_config: CrateCheckConfig,
+ pub config: Cfg<Symbol>,
+ pub check_config: CheckCfg<Symbol>,
```
Stop telling people to submit bugs for internal feature ICEs
This keeps track of usage of internal features, and changes the message to instead tell them that using internal features is not supported.
I thought about several ways to do this but now used the explicit threading of an `Arc<AtomicBool>` through `Session`. This is not exactly incremental-safe, but this is fine, as this is set during macro expansion, which is pre-incremental, and also only affects the output of ICEs, at which point incremental correctness doesn't matter much anyways.
See [MCP 620.](https://github.com/rust-lang/compiler-team/issues/596)
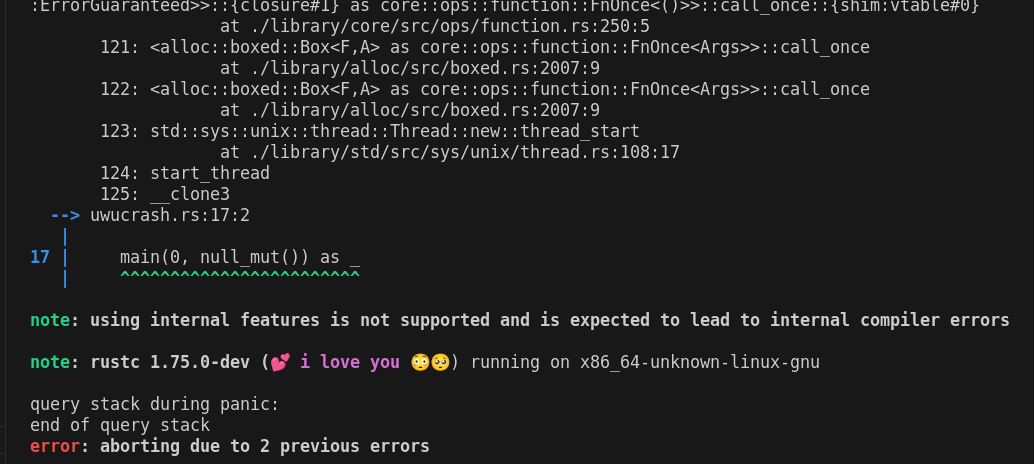
This keeps track of usage of internal features, and changes the message
to instead tell them that using internal features is not supported.
See MCP 620.