Moves our projection handling code into a common file, and avoids the use of a
general mplace-based fallback function by have more specialized implementations.
mplace_index (and the other slice-related functions) could be more efficient by
copy-pasting the body of operand_index. Or we could do some trait magic to share
the code between them. But for now this is probably fine.
don't allow ZST in ScalarInt
There are several indications that we should not ZST as a ScalarInt:
- We had two ways to have ZST valtrees, either an empty `Branch` or a `Leaf` with a ZST in it.
`ValTree::zst()` used the former, but the latter could possibly arise as well.
- Likewise, the interpreter had `Immediate::Uninit` and `Immediate::Scalar(Scalar::ZST)`.
- LLVM codegen already had to special-case ZST ScalarInt.
So I propose we stop using ScalarInt to represent ZST (which are clearly not integers). Instead, we can add new ZST variants to those types that did not have other variants which could be used for this purpose.
Based on https://github.com/rust-lang/rust/pull/98831. Only the commits starting from "don't allow ZST in ScalarInt" are new.
r? `@oli-obk`
There are several indications that we should not ZST as a ScalarInt:
- We had two ways to have ZST valtrees, either an empty `Branch` or a `Leaf` with a ZST in it.
`ValTree::zst()` used the former, but the latter could possibly arise as well.
- Likewise, the interpreter had `Immediate::Uninit` and `Immediate::Scalar(Scalar::ZST)`.
- LLVM codegen already had to special-case ZST ScalarInt.
So instead add new ZST variants to those types that did not have other variants
which could be used for this purpose.
interpret: use AllocRange in UninitByteAccess
also use nice new format string syntax in `interpret/error.rs`, and use the `#` flag to add `0x` prefixes where applicable.
r? ``@oli-obk``
Operand::Uninit is an *allocated* operand that is fully uninitialized.
This lets us lazily allocate the actual backing store of *all* locals (no matter their ABI).
I also reordered things in pop_stack_frame at the same time.
I should probably have made that a separate commit...
Change enum->int casts to not go through MIR casts.
follow-up to https://github.com/rust-lang/rust/pull/96814
this simplifies all backends and even gives LLVM more information about the return value of `Rvalue::Discriminant`, enabling optimizations in more cases.
fix interpreter validity check on Box
Follow-up to https://github.com/rust-lang/rust/pull/98554: avoid walking over parts of the value twice.
And then move all that logic into the general visitor so not each visitor implementation has to deal with it...
Interpret: AllocRange Debug impl, and use it more consistently
The two commits are pretty independent but it did not seem worth having two PRs for them.
r? ``@oli-obk``
interpret: don't rely on ScalarPair for overflowed arithmetic
This is for https://github.com/rust-lang/rust/pull/97861.
Cc `@eddyb`
I would like to avoid making this depend on `dest.layout.abi` to avoid a branch that we are not usually covering both sides of. Though OTOH this seems like fairly straight-forward code. But let's benchmark this option first to see how bad that extra `force_allocation` really is.
CTFE interning: don't walk allocations that don't need it
The interning of const allocations visits the mplace looking for references to intern. Walking big aggregates like big static arrays can be costly, so we only do it if the allocation we're interning contains references or interior mutability.
Walking ZSTs was avoided before, and this optimization is now applied to cases where there are no references/relocations either.
---
While initially looking at this in the context of #93215, I've been testing with smaller allocations than the 16GB one in that issue, and with different init/uninit patterns (esp. via padding).
In that example, by default, `eval_to_allocation_raw` is the heaviest query followed by `incr_comp_serialize_result_cache`. So I'll show numbers when incremental compilation is disabled, to focus on the const allocations themselves at 95% of the compilation time, at bigger array sizes on these minimal examples like `static ARRAY: [u64; LEN] = [0; LEN];`.
That is a close construction to parts of the `ctfe-stress-test-5` benchmark, which has const allocations in the megabytes, while most crates usually have way smaller ones. This PR will have the most impact in these situations, as the walk during the interning starts to dominate the runtime.
Unicode crates (some of which are present in our benchmarks) like `ucd`, `encoding_rs`, etc come to mind as having bigger than usual allocations as well, because of big tables of code points (in the hundreds of KB, so still an order of magnitude or 2 less than the stress test).
In a check build, for a single static array shown above, from 100 to 10^9 u64s (for lengths in powers of ten), the constant factors are lowered:
(log scales for easier comparisons)
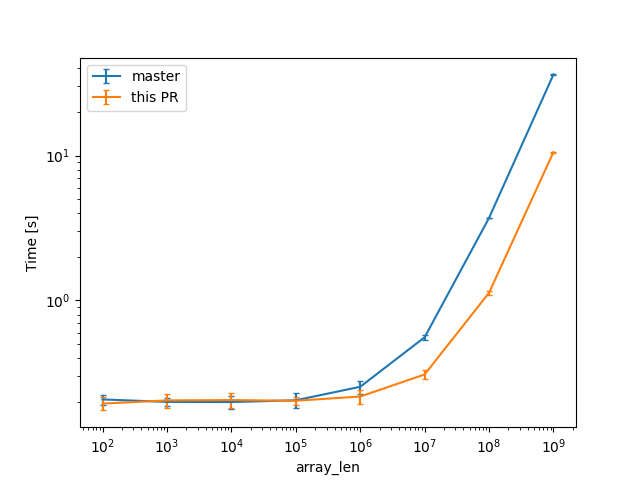
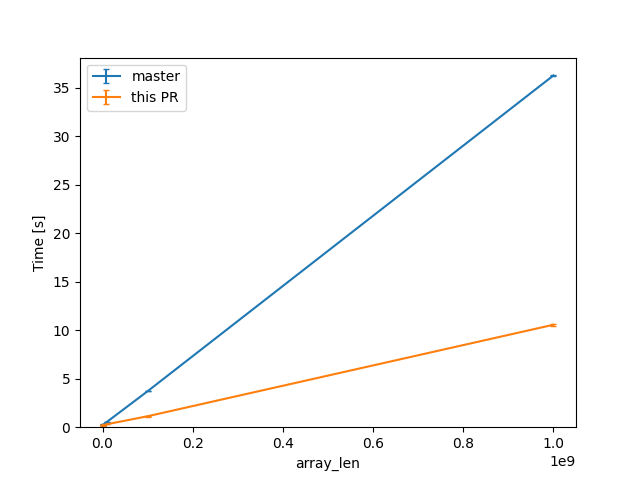
(linear scale for absolute diff at higher Ns)
For one of the alternatives of that issue
```rust
const ROWS: usize = 100_000;
const COLS: usize = 10_000;
static TWODARRAY: [[u128; COLS]; ROWS] = [[0; COLS]; ROWS];
```
we can see a similar reduction of around 3x (from 38s to 12s or so).
For the same size, the slowest case IIRC is when there are uninitialized bytes e.g. via padding
```rust
const ROWS: usize = 100_000;
const COLS: usize = 10_000;
static TWODARRAY: [[(u64, u8); COLS]; ROWS] = [[(0, 0); COLS]; ROWS];
```
then interning/walking does not dominate anymore (but means there is likely still some interesting work left to do here).
Compile times in this case rise up quite a bit, and avoiding interning walks has less impact: around 23%, from 730s on master to 568s with this PR.
Enable MIR inlining
Continuation of https://github.com/rust-lang/rust/pull/82280 by `@wesleywiser.`
#82280 has shown nice compile time wins could be obtained by enabling MIR inlining.
Most of the issues in https://github.com/rust-lang/rust/issues/81567 are now fixed,
except the interaction with polymorphization which is worked around specifically.
I believe we can proceed with enabling MIR inlining in the near future
(preferably just after beta branching, in case we discover new issues).
Steps before merging:
- [x] figure out the interaction with polymorphization;
- [x] figure out how miri should deal with extern types;
- [x] silence the extra arithmetic overflow warnings;
- [x] remove the codegen fulfilment ICE;
- [x] remove the type normalization ICEs while compiling nalgebra;
- [ ] tweak the inlining threshold.
interpret: make a comment less scary
This slipped past my review: "has no meaning" could be read as "is undefined behavior". That is certainly not what we mean so be more clear.
{kind=link}
{kind=link}