1.前言:为何一个词有2个向量
在cs224n 2019课程中的L1和L2中,我们详细论述了word2vec skip-gram 模型,相信大家都已经掌握了。
但这里有一个细节,肯定让不少同学非常疑惑。
视频中提到,一个词有2个向量,总参数是2d*V。

(Lecture 01 Introduction and Word Vectors,ppt第23页)提到了use two vectors per word
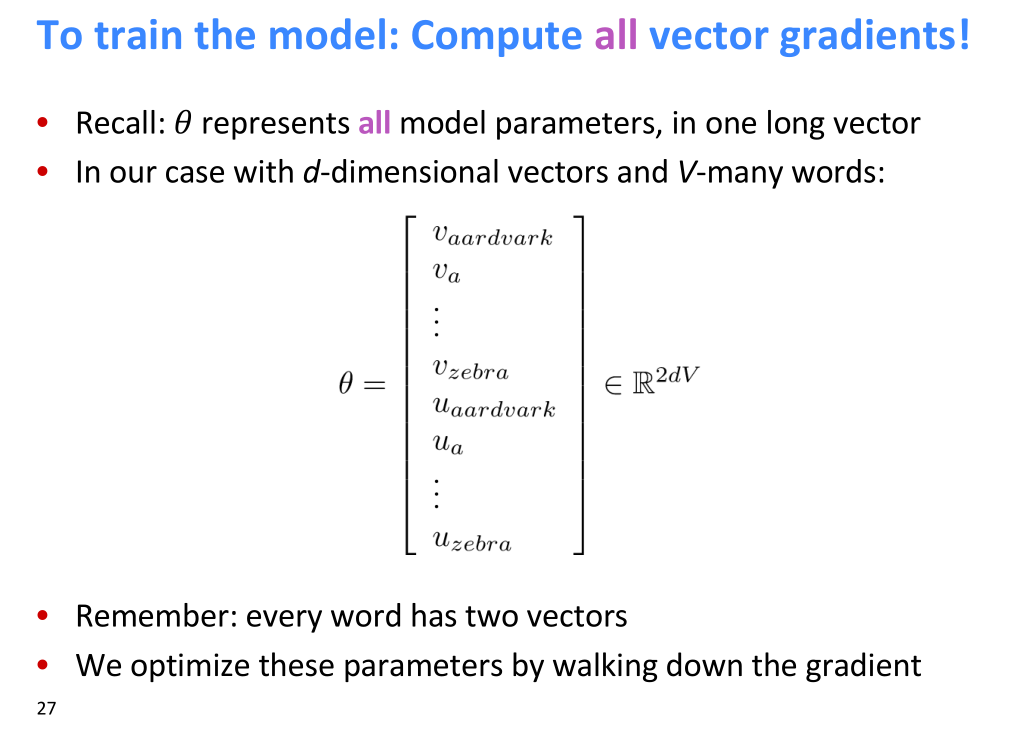
(Lecture 01 Introduction and Word Vectors,ppt第27页)
如上图示,在训练过程中是存在2个词向量的。这怎么理解?明明一个词最终输出的时候,只有一个词向量呀。
2.word2vec回顾
在视频中,Manning教授简单提了一嘴,我们这里详细说明一下,word2vec为什么要在训练的时候使用2个词向量,这2个词向量是什么关系,最终输出的是什么词向量。
这2个词向量一个是词$w$的word representations ($v_w$) 在下图中表示为V,一个是该词w的context representations ($u_w$)在下图中表示为U。
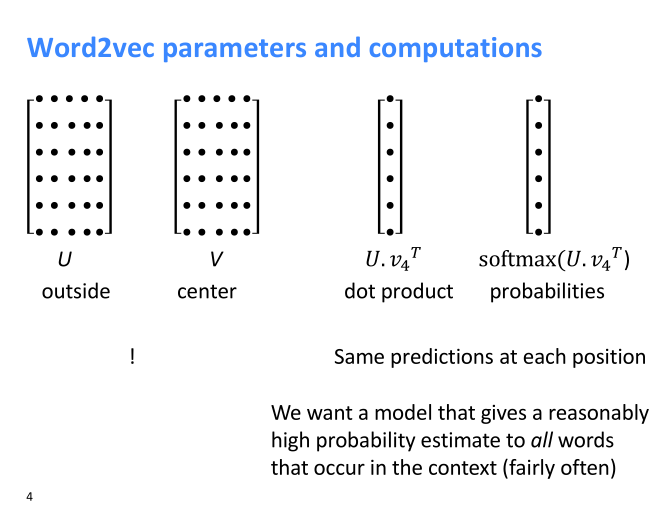
(Lecture 02 Word Vectors 2 and Word Senses ppt第4页)
在我们训练词向量的时候,对于训练语料,使得P(o|c)的概率最大,也就是
J=-logP(o|c)最小(如果没有负号则是求最大,cs224n视频的ppt就没有负号)。
我们是怎么定义P(o|c)的呢?
定义如下:
$P(o|c)={exp(u_o^Tv_c)}/{\sum_{w=1}^V exp(u_w^Tv_c)}$
可以看到,这个条件概率是中心词和上下文词2个词向量的点乘,再取e的指数,并除以所有词的词向量和中心词的点乘取e的指数之和,公式的本质是一个向量点乘+softmax。
这里当w是o 中心词的时候,使用词的word representations,而w是c上下文词的时候,使用词的context representations。
3.问:为什么要这么做呢,为什么不都使用同一个词向量呢?
答:使用2个词向量的目的是,训练时我们需要让具有相同上下文的词的词向量相互接近,但我们不希望这些词的上下文的词也相互接近。
以下面2句话的例子讲解一下:
the dog has a tail
the cat has a tail
这里采用word2vec skip-gram ,naive softmax 模型,窗口大小采用k=1。
对于中心词dog来说,需要计算:
P(dog|has)
P(dog|the)
对于中心词cat来说,需要计算:
P(cat|has)
P(cat|the)
这里的条件概率公式是上面的:
$P(o|c)={exp(u_o^Tv_c)}/{\sum_{w=1}^V exp(u_w^Tv_c)}$
分别把中心词dog/cat 和上下文词has/the带入,就可求出概率。
对于目标函数J=-logP(o|c),我们要求其最小值,那么在word2vec算法中,需要做梯度下降算法。这里使用sgd,只需要对每个样本进行梯度下降,如下公式:
$u_o(new)=u_o(old)-\alpha \partial J/(\partial u_o)$
$v_c(new)=v_c(old)-\alpha \partial J/(\partial v_c)$
多次迭代sgd后,会使得J变小,而$u_o$和$v_c$的点乘会变大,进而使得两者余弦距离接近。那么如果dog/cat 分别和has/the 接近了,dog和cat的词余弦距离就会接近。
假设这里$u_o$和$v_c$都是同一种向量,那么不光dog和cat的词余弦距离接近,cat和has也会相近,连has和the都会相近。
但是我们希望最后输出的词向量,dog和cat相近,但不希望cat和has相近,也不希望has和the相近。如果都相近,词就没有区分度了。
所以我们对于每个词采用双词向量,对于dog 这个词,有一个word representations ($v_c$) 用来作为中心词时计算,有一个context representations ($u_o$)作为上下文词时进行计算。
context representations训练为了使得中心词word representations相近,context representations作为中间结果不输出,而word representations作为最终结果输出。这样就避免了所有中心词的词向量都接近的困境了。
最终,我们保存中心词的word representations,既公式中的$v_c$ 。
4.考古
解释清楚这个问题以后,我们知道最早的算法是否使用2个vec的。
在word2vec提出者,Tomas Mikolov 的论文Distributed Representations of Words and Phrases and their Compositionality
和他提供的word2vec.c代码里,训练过程中,每个word都存在2个词向量。
如下图
论文Distributed Representations of Words and Phrases and their Compositionality 中截图
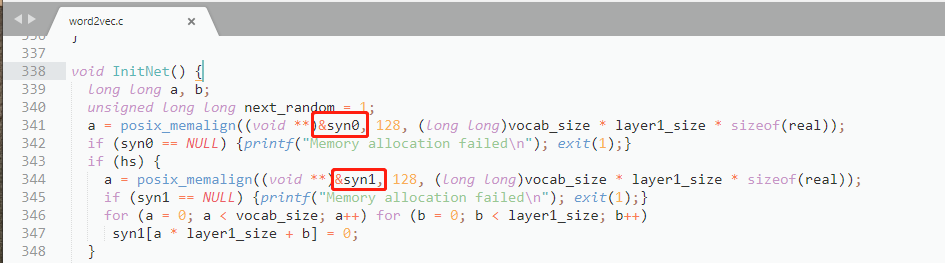
word2vec.c代码截图
所以我们清楚了,最早的word2vec算法确实在训练的时候是存在2个vec的。
5.参考文献:
https://www.quora.com/Why-does-word2vec-have-two-different-representation-for-words
论文:Distributed Representations of Words and Phrases
and their Compositionality