flypython群里有同学问我,如何从大量格式不确定的word文档抽取姓名、电话号码、邮箱等信息存入excel表格。通过之前我们的文章,他已经学会读取和写入文档和表格,但就是无法处理格式不确定的文档。这里介绍的正则方法,可以帮助他解决这个问题。
目标
15分钟内让你真正明白正则表达式是什么,并且让你可以在自己的python程序里正确使用它。
你将学会:
- 极简python使用正则的方法
- 如果利用python高效的匹配字符串
- 如何利用python正则进行文本判断、过滤、信息提取
0.极简正则入门
假设程序从word或者excel读取了一串字符串,字符串中有一部分是电话号码,现在需要完整提取这个电话号码。
1 | import re |
输出:
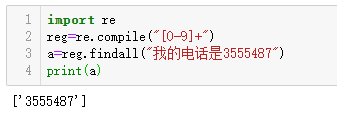
解释:"[0-9]+"是正则表达式,意思是匹配0-9的数字,"+"
表示可以匹配1次-多次,reg.findall表示从后面的字符串里找到所有的匹配值。
1.字符集
字符集,又叫元字符,就是用一些特殊符号表示特定种类的字符或位置。
匹配字符
| 代码 | 说明 |
|---|---|
. |
匹配除换行符以外的任意一个字符 |
\d |
匹配数字 |
\w |
匹配字母或数字或下划线或汉字 |
\s |
匹配任意的空白符 |
^ |
匹配字符串的开始 |
$ |
匹配字符串的结束 |
举例
1 | import re |
输出:
重复匹配
| 代码 | 说明 |
|---|---|
* |
重复0次-无数次 |
+ |
重复1次-无数次 |
? |
重复0次-1次 |
{m} |
重复m次 |
{m,n} |
重复m-n次 |
举例
1 | import re |
输出: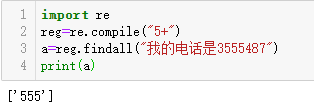
贪婪与懒惰
贪婪:匹配尽可能长的字符串
懒惰:匹配尽可能短的字符串
懒惰模式的启用只需在重复元字符之后加?既可。
*?重复任意次,但尽可能少重复+?重复1次或更多次,但尽可能少重复??重复0次或1次,但尽可能少重复{n,m}?重复n到m次,但尽可能少重复{n,}?重复n次以上,但尽可能少重复
举例
1 | import re |
输出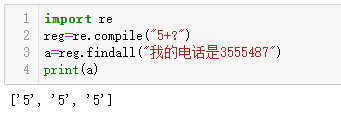
注意:
如果想匹配元字符本身或者正则中的一些特殊字符,使用\\转义。
这里介绍的正则内容是最基础的,想要了解更详细的正则表达式语法,请参考:
2.利用正则判断
判断
有时候我们想利用正则表达式对用户输入进行判断,比如判断用户输入的身份证号是否符合规则,那么可以这样写:
1 | import re |
输入结果
说明:^字符表示必须匹配字符串开头;$表示必须匹配字符串结尾。
过滤
假设,输出一串文本,只想保留汉字,去除特殊符号。代码如下:
1 | import re |
输入结果:
查找位置
查找某个文本在字符串中的位置,一般用于信息提取。
1 | import re |
输出结果

人生苦短,我用python早下班。如果觉得不错,对你工作中有帮助,请长按下面二维码关注我们。(回复训练营加群,一起探讨python问题)
